I290 eyetracking
Eye tracking experiment web pages
Presentation

Project Goals
The goal of our project is to identify subjects’ eye gaze patterns when they are reading on a screen while listening to accompanying audio, either synchronized (verbatim) speech or non-synchronized natural speech and to measure comprehension of the content read/heard. We also compare this with gaze patterns and comprehension for a single stimulus (only text or only audio).We use this to gain insight that might help us make a case for (or against) audio-assisted reading.
Background
We stumbled on this idea while brainstorming with Prof. Marti Hearst at the I School, Berkeley. She was very interested in audiobooks and their effectiveness in reading and comprehension. We thought eye-tracking provided by the SMI Eye-tracking system device would be a great way to validate existing hypotheses and research about audio-assisted reading by giving evidence of readers’ eye gaze patterns, especially parameters like fixation, saccades, etc.
Experiment Design
We designed an experiment with 4 variants:
1. Text only
2. Audio only
3. Audio synchronized with text (verbatim)
4. Audio unsynchronized with text (lecture/talk format, free form, with text as a more formal and verbose reference)
We recruited participants on a voluntary basis and gave each of them two comprehension tasks - one with single stimulus content and the other with double stimulus content. We assigned them randomly to any of the following four comparison groups:
a) Text alone versus Synchronized audio-assisted text
b) Audio alone versus Synchronized audio-assisted text
c) Text alone versus Unsynchronized audio-assisted text
d) Audio alone versus Unsynchronized audio assisted text
We were interested in the above 4 specific groups and not all combinations of 4 variants.
Before the experiment, participants were given information and instructions about the experiment as well as a consent form. After the experiment, we collected their self-reported English proficiency level (text and audio were in English)
on the ILR scale and general demographic information(age, gender) and also asked them informal, qualitative questions about their experience.
In the actual experiment, participant were required to do 2 comprehension tasks. Each task had about 4 minutes of reading and/or listening (with the goal of answering some questions later, which they were informed about before they started). After the reading/listening they were presented with a set of questions based on the text/audio. Questions were multiple choice and a mix of inference/reasoning (E.g. What do you think was the cause of X?) and recall (e.g. How many days did the person A do X? ) related. They were not timed (they could take as much time to answer a question) and we recorded time taken for questions. The reading/listening, however, was timed. Participants were not allowed to refer back to the text while answering questions, so we took this into consideration while setting the questions. They were also not allowed to take notes during the reading/listening nor to pause the audio and read for longer.
We recorded the eye-gaze data for each experiment. For audio only, we had a static image consistent with the context of the content instead of accompanying text and we didn’t really record their gaze. We did, however, measure the same while the participant answered questions. During questions, we expected the fixations on different words in the questions/options to give us a hint about dubiousness and deliberation when faced with the question, difficulty level of the question, etc. whereas the lack of fixation could suggest confidence level or carelessness while answering the question. We also got mouse-click data which gave us a hint about uncertainty during questions if a person switched between answer options multiple times before submitting an answer.
We used content from http://www.manythings.org/listen/
This has a repository of texts with accompanying audio. We selected two:
http://www.manythings.org/voa/how/2076.html (for single stimulus)
http://www.manythings.org/voa/things/7027.html (for double stimulus)
Each subject received both of these. The texts and questions did not require/assume any specialized prior knowledge on the part of the participants in order to comprehend. We built web pages using this text and embedded the respective audio files in them. These web pages were used to run the experiments.
We used the Reading Comprehension sample questions of the ETS to model our questions based on the content.
For the unsynchronized audio, we recorded a natural, informal rendition of the text in our own voice and words, retaining all the essential facts while leaving out extraneous formal details. Here the content was interspersed with natural expressions, emphasis, repetitions, prompts etc. as deemed necessary.
We used time taken to answer questions and the accuracy of the answers for each task as our metrics to measure effectiveness of comprehension.

Considerations
We controlled the experiment by following steps:
Some pictures from the experiment -


Evaluation
Once the participants completed the experiment, we did a small qualitative interview to understand and record their experience. Some questions we asked them were:
We also showed them the gazing patterns immediately and let them walk us through what/how they read the text. This was interesting and useful for us to know and correlate to the findings from their gaze patterns and comprehension performance metrics.
Results
Gaze patterns
This video shows the gazing patterns for two users reading text. There was no audio involved in this case.
This video shows the gazing patterns for two users reading text alongwith unsynchronized/paraphrased audio being played in the background.
This video shows the gazing patterns for two users reading text alongwith synchronized audio being played in the background.
Key observations from gazing patterns
- People fixate more on nouns, beginning of paragraphs and fact-rich areas
- Saccades in text only and sync audio groups are more linear
- Saccades in unsync audio are all over the place
- Some people read the beginnings of paragraphs and trail off, mentally predicting/inferring the remaining sentence
- Some people concentrate on the middle of paragraphs which have more facts and neglect the noise in the text
- People keep backtracking to comprehend/retain facts when they know they will be tested on them later
- Got insight on uncertainty and deliberation during questions through fixation, saccades and mouse clicks
- Mixed reactions to single stimulus vs. two stimuli
- People liked natural, reinforcing/introductory prompts in unsync. audio
Measuring reading comprehension
| Task | Average Accuracy | Average Time |
|---|---|---|
| Audio | 77% | 12023ms |
| Text | 73% | 12606ms |
| Text + Audio Synchronized | 73% | 11526ms |
| Text + Audio Unsynchronized | 60% | 9953ms |
Results
| Case | Average Time(ms) | Average Accuracy | |||
|---|---|---|---|---|---|
| Part 1 | Part 2 | Part 1 | Part 2 | Part 1 | Part 2 |
| Text | Sync Audio | 11637 | 11988 | 70% | 70% |
| Audio | Sync. Audio | 13511 | 12210 | 100% | 90% |
| Text | Faster Audio | 13418 | 10445 | 80% | 70% |
| Audio | Faster Audio | 8968 | 11461 | 60% | 60% |
| Text | Unsync. Audio | 12765 | 10307 | 70% | 60% |
| Audio | Unsync. Audio | 13591 | 9600 | 70% | 60% |
| Participant | Single Stimulus(Part 1) | Double Stimulus(Part 2) | ||
|---|---|---|---|---|
| ID | Preference | Accuracy | Preference | Accuracy |
| 1 | Yes | 100% | No | 80% | 2 | Yes | 100% | No | 100% | 3 | Yes | 80% | No | 80% | 4 | No | 60% | Yes | 60% | 5 | No | 100% | Yes | 80% | 6 | No | 60% | Yes | 80% | 7 | No | 60% | Yes | 40% | 8 | No | 60% | Yes | 60% | 9 | No | 80% | Yes | 60% | 10 | Yes | 60% | No | 60% | 11 | Yes | 80% | No | 60% | 12 | Yes | 60% | No | 60% |
More visualizations used for analysis:
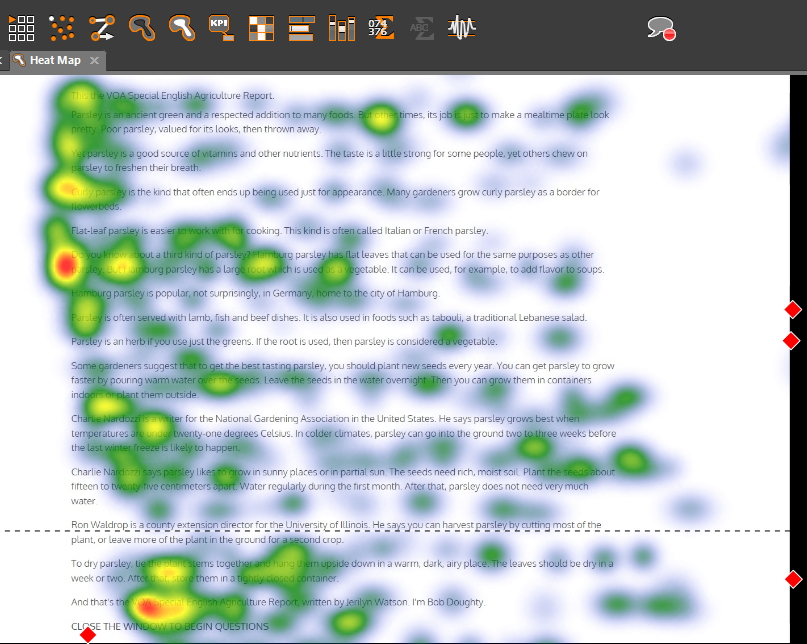 Image showing heatmap for reading patterns for a subject
Image showing heatmap for reading patterns for a subject
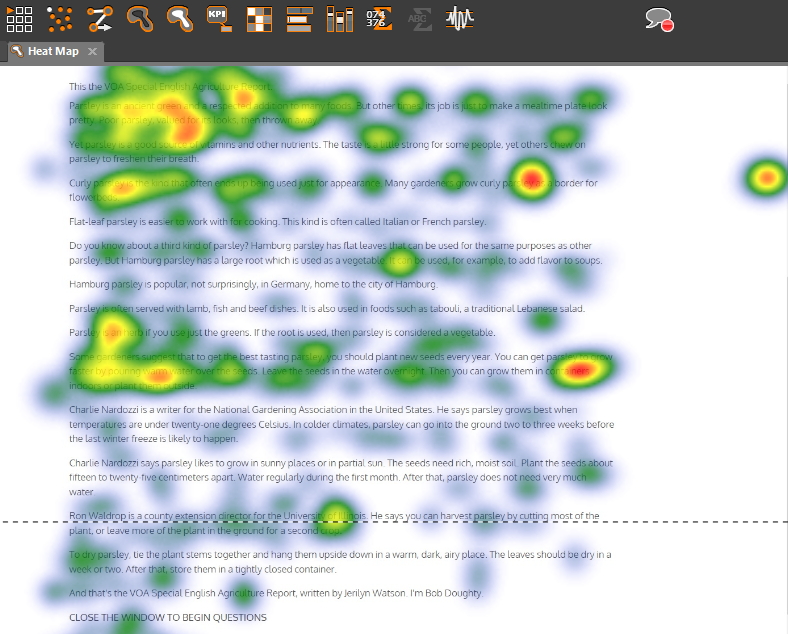 Image showing heatmap for reading patterns for a subject
Image showing heatmap for reading patterns for a subject
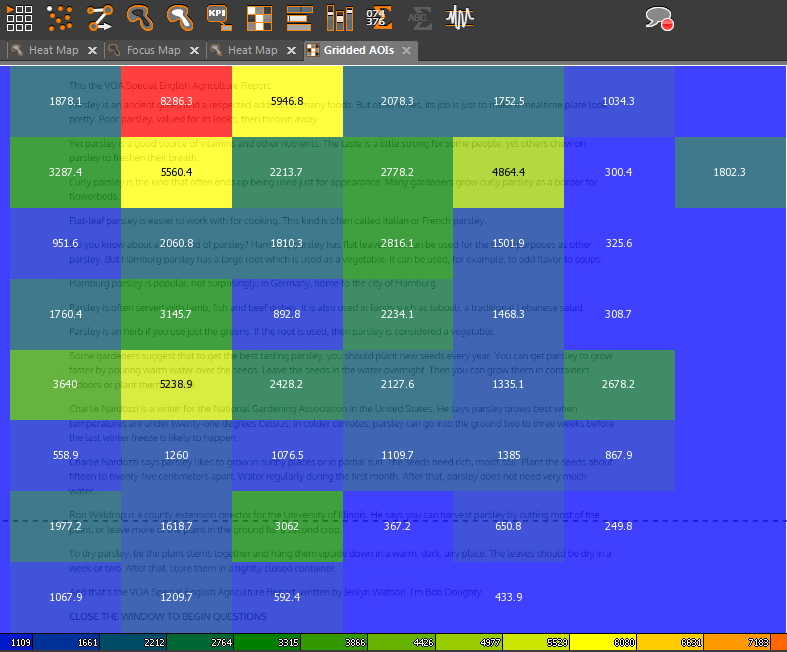 Image showing heatmap for specific regions for reading patterns for a subject
Image showing heatmap for specific regions for reading patterns for a subject
 Image showing focus map for reading patterns for a subject
Image showing focus map for reading patterns for a subject
 Image showing focus map for reading patterns for a subject
Image showing focus map for reading patterns for a subject
Qualitative feedback
Future scope/work
Limitations
Links
References